队列、AQS和锁
CopyOnWriteArrayList
应用于读多写少的环境中,根据类注释,可以直到在所有可变操作(add、set和remove)的时候是创建底层数组副本来实现的。
从源码来看,get操作是直接没有锁和同步操作的,操作的就是原始的数组。
set操作先用ReentrantLock来获取锁,然后拷贝原数组的备份,在其基础上进行修改,最后用setArray方法来替换原数组。add方法也类似,但是在数据增长方面,没有了扩容控制,而是使用了Arrays.copyOf直接返回一个数据加一的新数组。而从固定位置插入的方法则使用System.arrayCopy方法进行操作
ConcurrentLinkedQueue
一个基于链表节点实现的无界线程安全队列。
当许多线程共享一个公共集合时,ConcurrentLinkledQueue是一个合适的选择。
迭代器是弱一致的,返回的元素反映了队列在迭代器创建时或创建后某个时刻的状态,它不抛出ConcurrentModificationException,并且可以与其他操作并发进行。包含在队列里面的元素都将被返回一次。
BlockingQueue
BlockingQueue在处理一个操作不能被立即满足但是能在未来某个时刻被满足的四种情况:
抛出异常
返回特殊值
阻塞当前线程的执行直到条件被满足
在给定的最大时间内进行阻塞

BlockingQueue不接受null,有容量限制,主要实现生产者-消费者队列,但是还支持Collection接口,其实现是线程安全的,所有队列方法都使用内部锁或者其他并发控制方式;其本质上不支持任何的colse和shutdown操作。
内存一致性问题:将对象放入一个BlockingQueue的操作要发生在将对象从另一个线程中BlockingQueue移除操作之前
当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
ArrryBlockingQueue
由数组构成的有界阻塞队列。这是一个经典的“有界缓冲区”,其中固定大小的数组包含由生产者插入并由消费者提取的元素。容量一旦创建,就不能更改。将元素放入满队列的尝试将导致操作阻塞;从空队列中获取元素的尝试也将类似地阻塞。此类支持可选的公平策略,用于对等待的生产者和消费者线程进行排序。默认情况下,不保证此顺序。但是,在公平性设置为true的情况下构建的队列将按FIFO顺序授予线程访问权限。公平通常会降低吞吐量,但会降低可变性并避免饥饿。
对于并发的控制,使用ReentrantLock加上两个Condition条件控制的。在put和take操作的时候,都需要通过ReentranLock获取锁,最终调用实际的enqueue和dequeue,通过两个condition条件来传递信号。
1 | /* |
LinkedBlockingQueue
双锁算法的变体。putLock和takeLock在等待操作时候需要条件,由ReentrantLock进行实现,依赖count字段作为原子维护,以避免在大多数情况下需要同时获取两个锁。 这其实相当于有两个ReentrantLock和两个Contion条件来共同实现保证状态
提供读者和写着的可见性:当元素入队时,putLock获取锁并更新count,后续的读者通过putLock或者takeLock获取入队节点的可见性,读者n = count.get(),这将获取前n个Node的可见性。
默认构建不设置大小,将会将capacity设置位Integer.MAX_VALUE,这也就相当于可以构建一个虚假意义的无界队列
1 | /** Lock held by take, poll, etc */ |
PriorityBlockingQueue
这个不保证相同优先级的元素排序,如果需要排序,可以自定义辅助键来打破优先级。
由基于数组的二叉堆进行实现,用一个ReentrantLock锁来保护公共操作。在resize的时候,使用简单的自旋锁来保证take操作进行分配,这就避免了等待的消费者的一再等待随之而来的因素累积。
默认的情况下使用自然排序,也可以通过自定义类实现 compareTo方法来指定元素排序规则,或者初始化时通过构造器参数 Comparator来指定排序规则。
1 | private static final int DEFAULT_INITIAL_CAPACITY = 11; |
在使用tryGrow方法扩容的时候,目前容量小于64,那么就是2 * oldCap + 2,大于64的时候就是原来的1.5倍。
线程池
使用线程池的好处:
- 降低资源消耗
- 提高响应速度
- 提高线程的可管理性
线程池大小的确定(n为内核数量,超线程那种):
- CPU密集型$n+1$:因为消耗的时cpu资源,应该尽可能的增加计算机资源
- IO密集型$2n$:需要进行的大量的io操作,cpu的压力小,应该尽可能的利用io效率
Executor
基础
Executor接口并不是严格 要求异步执行,一般情况是任务在调用之外的线程中执行,许多Executor的实现对任务的调度情况加以限制。
执行的任务需要实现Runable和Callable接口。
主要由三部分构成:
- 任务
- Executor
- 结果
阿里的开发建议上不允许使用Executors去创建线程池,原因如下:
FixedThreadPool和SingleThreadExecutor允许的等待队列是Integer.MAX_VALUE,会造成大量的线程堆积CachedThreadPool和ScheduleldThreadPool允许创建为Intreger.MAX_VALUE数量的线程,极端环境下也能造成大量线程堆积
线程池解决了两个不同的问题:
- 由于减少了每个任务的调用开销,它们通常在执行大量异步任务时提高了性能,并且它们提供了一种绑定和管理执行任务集合时消耗资源的方法
- 维护一些基本统计信息
提供了了一下几个工厂方法,底层是基于ThreadPoolExecutor实现的:
Executors.newCachedThreadPool无界线程池,具有自动线程回收的功能。从源码上看,corePoolSize被设置为0,maximumPoolSize被设置为Integer.MAX_VALUE,keepalive被设置为60,工作队列用SynchronousQueue实现。当提交的任务速度大于执行任务的速度时候,就会导致不断创建工作线程,最终导致cpu和内存资源耗尽。Executors.newFixedThreadPool创建固定线程数量的线程池。从源码可以看出,corePoolSize和maximumPoolSize都是传入的nThreads,然后执行的workQueue是LinkedBlockingQueue。不推荐的原因是他的等待队列是默认构造的LinkedBlockingQueue并且corePoolSize和maximumPoolSize相等的原因,导致不可能存在任务队列满的情况,keepAliveTime被设置为0,等待队列默认数量是Intger.MAX_VALUE,极端情况下会占满整个workQueue,最后导致oomExecutors.newSingleThreadExecutor,从源码可以看出,corePoolSize和maximumPoolSize都是1,工作队列使用LinkedBlockingQueue来实现,keepalive被设置为0,所以也会和Executors.newFixedThreadPool一样造成oom
推荐使用ThreadPoolExecutor去创建线程池
ThreadPoolExecutor
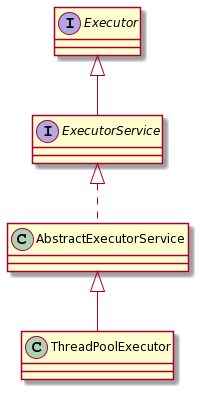
构造
其构造原理比较简单,就是些赋值操作,但是以下参数比较重要
corePoolSize:定义了最小可以同时运行的线程数量maximumPoolSize:线程池中允许的最大线程数量workQueue:在执行当前任务前会判断是否达到最大线程数量,达到就被存放到队列中handler:拒绝异常处理器,用于处理当前线程池达到最大执行容量,workqueue也满的情况这个接口有四个实现类,代表了四种处理策略,实现的四个类作为ThreadPoolExecutor的四个内部类

AbortPolicy:抛出RejectedExecutionException,这个是默认的拒绝测率CallerRunsPolicy:调用线程的execute方法执行代码,如果executor关闭,则丢弃任务DiscardOldestPolicy:丢弃最早未处理的线程DiscardPolicy:不处理新任务,直接丢弃
对于可伸缩的应用程序,最好使用CallerRunsPolicy策略。
原理
使用ReentrantLock作为全局锁来控制并发
在一个新任务提交时,运行的corePoolSize小于corePoolSize时,即使其他任务存在空闲,一个新线程将被创建用于执行该任务。当运行的线程数大于corePoolSize小于maximumPoolSize时,则只会在workQueue满的时候才会创建新的线程。
默认情况下,即使是核心线程也只在新任务到达时初始创建和启动,但是可以使用prestartCoreThread或prestartAllCoreThread方法动态覆盖。
默认使用ThreadFactory创建新线程。如果未另行指定,则使用Executors.defaultThreadFactory,它创建的所有线程都位于同一ThreadGroup中,并且具有相同的NORM_PRIORITY优先级和非守护进程状态。
可以阅读ThreadPoolExecutor的execute的代码,在开头的注释中,将整个执行过程分成了三个步骤:
- 如果正在运行的线程少于
corePoolSize,则调用addWorker(command,true)增加一个线程,并使用此线程运行任务 - 任务已经排队成功,也就是运行任务数量大于
corePoolSize,则先要判断当前线程池是否关闭,然后还得再次获得线程池状态,如果线程池不是RUNNING状态则要从任务队列中移除任务,还得检查线程是否全部执行完毕,同时执行拒绝操作,还得检查线程池是否为空,为空则增加线程 - 无法将任务放入队列,则尝试使用
addWorker添加一个线程,如果失败通过reject()执行相应的拒绝策略
常见对比
Runable和Callable
Runable不返回结果或抛出检查异常
Callable返回结果和异常
execute和submit
execute用于提交不需要返回值的任务,所以无法判断任务是否呗线程池执行与否
submit用于提交需要返回值的任务,线程池会返回一个Future对象
shutdown和shutdowNow
shutdown() :关闭线程池,线程池的状态变为 SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕。
shutdownNow() :关闭线程池,线程的状态变为 STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List<Runable>,除了尽力尝试停止处理正在积极执行的任务之外,没有其他保证。此实现通过Thread.interrupt取消任务,因此任何无法响应中断的任务都可能永远不会终止。
ScheduledThreadPoolExecutor
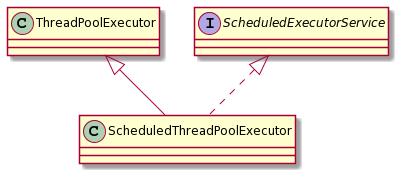
主要用来在给定的延迟后运行任务,或者定期执行任务。但是在实际业务中,会使用Quartz等调度框架。
原理
此类通过以下方式实现ThreadPoolExecutor:
- 使用自定义类型的
ScheduledFutureTask - 使用自定义无界
DelayQueue的变种DelayedWorkQueue,与ThreadPoolExecutor相比,corePoolSize和maximumPoolSize相同有效简化了一些相同的执行机制 - 支持可选的关机后运行参数
- 允许拦截和插装的任务修饰方法
在构造方面,corePoolSize是传入的构造,maximumPoolSize则是被设置为Integer.MAX_VALUE,keepalive为0,这就导致了在极端情况下,也就是提交任务的速度一直大于线程池中执行线程的速度,就会一直新增工作线程,导致耗尽系统资源。
使用DelayedWorkQueue作为任务的排队队列,是一个基于堆的数据结构,每个ScheduledFutureTask还要将其索引记录到堆数组中
执行过程
- 当调用
scheduleAtFixedRate方法时,会构建一个ScheduledFutureTask对象并添加到DelayedWorkQueue中,期间使用decorateTask将其转换成RunnableScheduledFuture对象 - 使用
delayedExecute获取DelayedWorkQueue中的任务,然后执行
Author: moyu-x
Link: http://moyu-x.com/2020/08/13/202008/BlockingQueueAndLock/
License: 知识共享署名-非商业性使用 4.0 国际许可协议