多线程基础
Contents
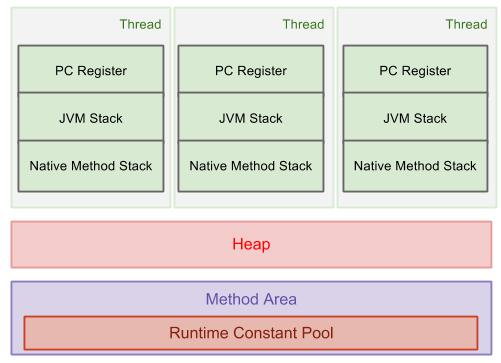
同类的多个线程共享堆的方法区,但每个线程拥有自己的程序计数器、虚拟机栈和本地方法栈。
死锁的形成一定能在状态上找到一个环,可以参考死锁产生的必要条件:1. 互斥条件;2.请求与保持;3.不剥夺条件;4.循环等等
从底层看sleep是将线程退出临界区,他一定会再次进入临界区,所以不会释放锁;而wait方法也是退出执行,但是他不一定会再次使用,如不释放锁则会造成死锁,所以要将锁释放;其主要区别是再与语义实现上。
用start方法开启线程会使线程进入就绪状态,而run从语义上是立即执行,相当于直接在当前线程执行代码。
Runnable 接口不会返回结果或抛出检查异常,但是Callable接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用Runnable接口,这样代码看起来会更加简洁。工具类Executors可以实现Runnable对象和Callable对象之间的相互转换。
查看AbstractExecutorService接口的submit方法,可以看到调用newTaskFor的方法返回了一个FeautreTask对象,而execute则是执行相关代码
synchronized
synchronizied早期属于重量级锁,其使用监视器锁进行实现,监视器锁利用系统的信号量实现,所以在使用过程中必然包含大量的上下文切换操作。
其在修饰静态方法时,由于静态方法属于类,所以实际是给类上了锁。
同步语句块
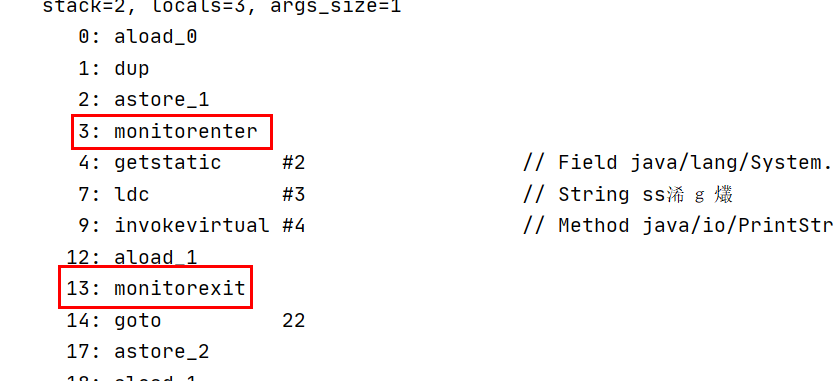
通过简单的demo,并且进行反编译class文件,我们可以看到明显的两个指令monitorenter和monitorexit,这中间包裹的就是同步代码块。
修饰方法
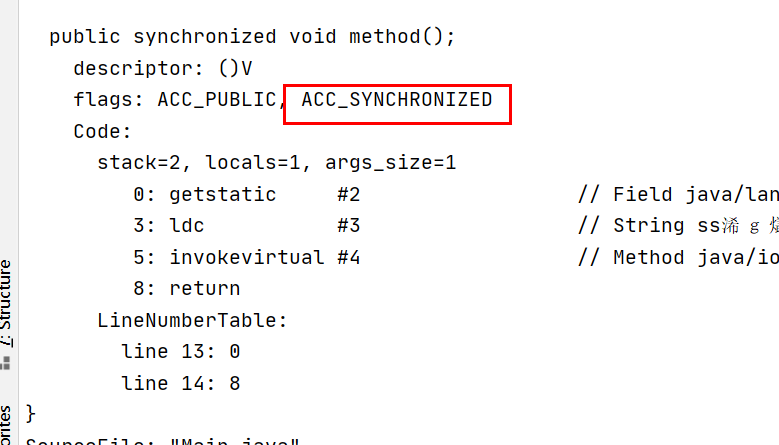
使用ACC_SYNCHRONIZED来表明这是一个同步代码块,在调用方法时就开始同步
和ReentrantLock的比较
- 两个都是可重入锁,也就是不会堵塞其他线程获取锁
- synchronized依赖于jvm实现,从class文件可以看出;
ReentrantLock依赖于API,灵活度较高,所以可以实现ReentrantLock提供了能够中断等待锁的线程机制ReentrantLock可以构建是公平锁还是非公平锁- 可以选择性通知,通过
condition类可以很好实现选择性通知
和volatile对比
首选我们得先确定volatile不是一个锁,只是一个同步语义操作,目的是为了防止含有此修饰操作的指令重排,所以在没有锁的特性的情况下会有部分锁同步的特性,所以具体的有一下不同
volatile是线程同步的轻量级别实现,性能比synchronized好,但是不能替代,毕竟场景不一样- 由于只是一个同步操作,所以不会发生阻塞(毕竟底层只是防止了指令的重排),而
synchronized是一个锁,所以会发生阻塞 volatile是同步语义操作,所以只能保证可见性,但是不能保证原子性volatile防止了指令重排,虽然重线程层面是多线程操作,但是从内部操作看,其防止指令重排强制线程对数据的访问变成有序的,所以只能作用于变量上面;而synchronized是一个锁操作,其虽然依赖于系统的信号量实现,但是其目的是保证资源同步,相当于强制要求多个线程对资源访问是有序的。
ThreadLocal
从类注释中,可以得到其提供了一个线程访问局部变量的工具,每个访问变量的线程都有自己独立初始化的变量副本。实例通常放在与之管理的私有化的静态域中。当每个变量访问结束后,这个变量都会被回收,除非还有其他引用没有结束。
原理
对于其如何发挥作用的,得先从get方法看起,在获取当前线程后,用getMap来获取具体的线程实例,通过getMap方法,我们来到了Thread类中维护的threadLocals变量,这个时候就会发现这个地方维护了一个定制化的map来存数据,用this来得到当前线程的变量副本,这里的this表示的是当前线程对threadlocal的引用,不为空就返回。为空就说明是第一次调用,去进行初始化操作,对于set方法也是一致的,只有某一个线程第一次调用get或set才会对其进行初始化操作。
然后通过set方法,可以确定threadlocalmap的key是线程的引,只有第一次调用才会去创建map。get方法的初始化在map创建后,会用null作为值,没创建调用createmap构建ThreadLocalMap。
综上,可以看出值是存储在ThreadLocalMap中,而这个值维护在Thread中,而不是将值存在ThreadLocal里面,这只是做了个引用。
内存泄漏
因为ThreadLocal是以类本身作为key存入ThreadLocalMap中,ThreadLocalMap的Entry在源码上是一个WeekRefrence的修饰,是个弱引用,所以当一个使用ThreadLoal的线程使用结束,这个时候如果被gc,会出现key为null的情况,最后导致这个ThreadLocal容器一直都不会被回收。所以为了解决这个问题,get、set以及remove都会调用expungeStaleEntry清除null为键值的数据。
Executors
阿里的开发建议上不允许使用Executors去创建线程池,原因如下:
FixedThreadPool和SingleThreadExecutor允许的等待队列是Integer.MAX_VALUE,会造成大量的线程堆积- CachedThreadPool和ScheduleldThreadPool允许创建为Intreger.MAX_VALUE数量的线程,极端环境下也能造成大量线程堆积
ThreadPoolExecutor
正确环境下我们应该使用这个方法去创建线程池
构造
其构造原理比较简单,就是些赋值操作,但是以下参数比较重要
corePoolSize:定义了最小可以同时运行的线程数量
maximumPoolSize:线程池中允许的最大线程数量
workQueue:在执行当前任务前会判断是否达到最大线程数量,达到就被存放到队列中
handler:拒绝异常处理器,用于处理当前线程池达到最大执行容量,workqueue也满的情况
这个接口有四个实现类,代表了四种处理策略,实现的四个类作为ThreadPoolExecutor的四个内部类

AbortPolicy:抛出RejectedExecutionException,这个是默认的拒绝测率CallerRunsPolicy:调用线程的execute方法执行代码,如果executor关闭,则丢弃任务DiscardOldestPolicy:丢弃最早未处理的线程DiscardPolicy:不处理新任务,直接丢弃
对于可伸缩的应用程序,最好使用CallerRunsPolicy策略。
原理
可以阅读ThreadPoolExecutor的execute的代码,在开头的注释中,将整个执行过程分成了三个步骤:
- 如果正在运行的线程少于
corePoolSize,则调用addWorker(command,true)增加一个线程 - 任务已经排队成功,则先要判断当前线程池是否关闭,然后还得再次获得线程池状态,如果线程池不是
RUNNING状态则要从任务队列中移除任务,还得检查线程是否全部执行完毕,同时执行拒绝操作,还得检查线程池是否为空,为空则增加线程 - 无法将任务放入队列,则尝试添加一个线程,如果失败通过
reject()执行相应的拒绝策略
Atomic类
原理
核心原理用AtomicIntenger来分析,其主要在初始化的利用unsafe类工具,使用cas+volatile来保证方法的原子操作,利用objectFieldOffset这个方法直接从内存中获取存储值的地址,从而直接获取导致,另外用volatile进行修饰以组织指令重排而强制让访问此变量的是顺序的。
1 | // setup to use Unsafe.compareAndSwapInt for updates |
AtomicStampedReference
AtomicStampedReference内部维护一个Pair类,通过此类内部stamp来表示修改状态,以此来解决ABA问题
1 | private static class Pair<T> { |
AtomicMarkableReference
同AtomicStampedReference一样内部维护了一个Pair类,但是用Boolean 值mark作为修改标识,只有两个版本,这知识降低了ABA问题发生的概率,但是不能彻底解决
1 | private static class Pair<T> { |
Author: moyu-x
Link: http://moyu-x.com/2020/08/06/202008/Muiti-Thread/
License: 知识共享署名-非商业性使用 4.0 国际许可协议